


Introduction
Generative AI, or Gen-AI, is making waves in technology, thanks to innovations like OpenAI’s GPT-3. It’s transforming how we interact with technology, from automating email responses in Gmail to enhancing code and documentation quality with tools like Github Copilot.
Lyearn is an employee experience platform offering goal tracking, meetings, task management, feedback sharing, and personalized learning. We employ generative AI to enhance user experiences, automate tasks based on feedback, generate key results from objectives, and create quizzes and articles for specific topics.

Example 1: Article Generation from the Topic name in the Learning Module
Imagine a scenario in which you provide a topic name, and the entire article is generated. You can then leverage Gen-AI features to enhance comprehension or insert paragraphs for specific sub-topics, which are also generated through LLMs. Consider the time savings! However, it’s important to view Gen-AI as a tool; manual efforts are still necessary to maximize the effectiveness of the task.

Example 2: Generating Key Result Suggestions from Objective Name in OKRs Module
In this article, we will look into designing a system through which you can leverage Artificial Intelligence as a Service platform or self-hosted LLM and enhance the user experience.
System Diagram
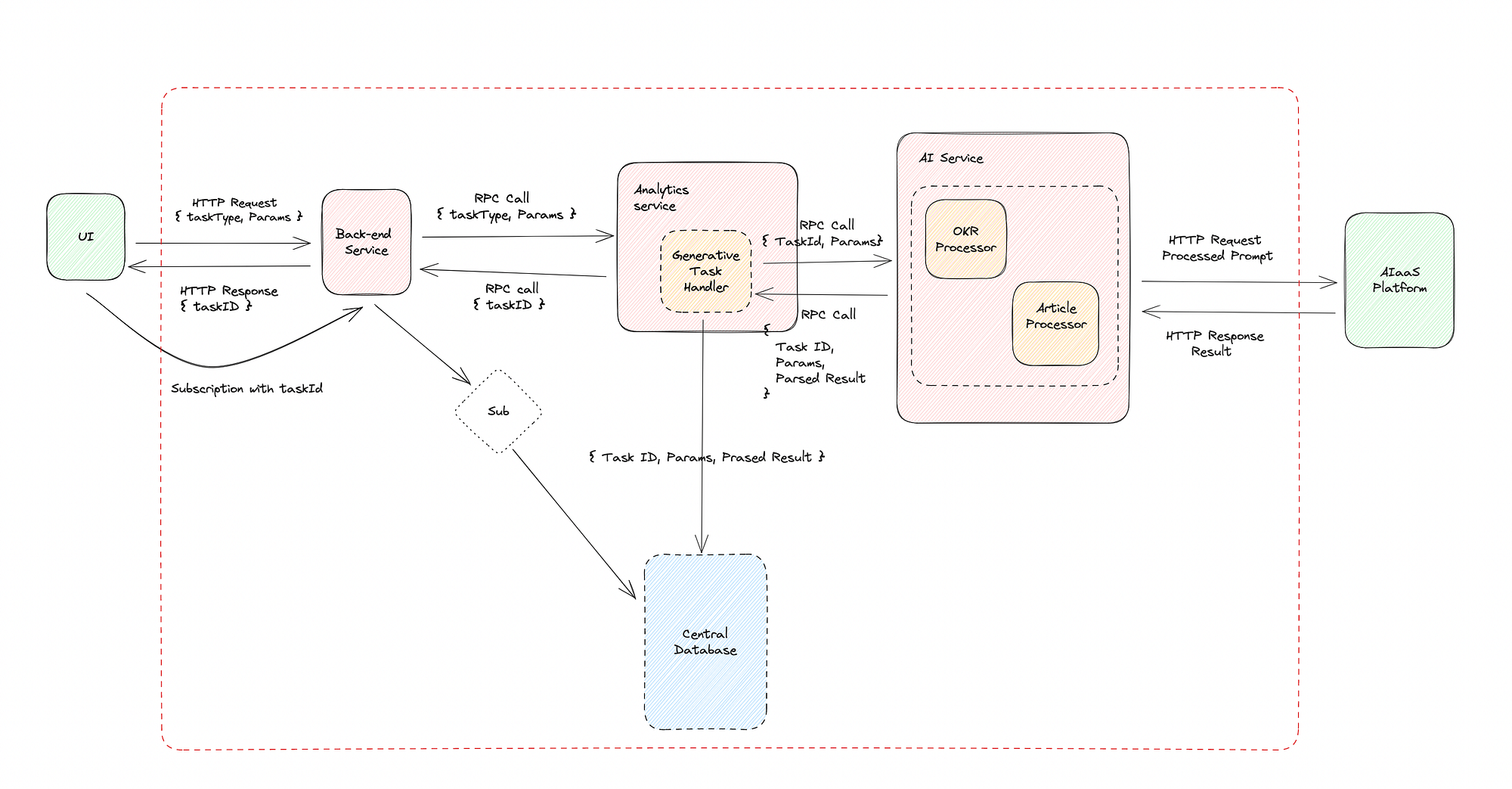
First, let’s discuss all the elements of the system. In this example, we are using a micro-services architecture, but the principles apply similarly to a monolithic system.
Back-end Service: This serves as the primary interface through which the UI interacts with the back-end APIs. It utilizes other services based on requests received from the UI.
Analytics Service: This service is responsible for interacting with the database. The back-end service sends requests for generative AI tasks with corresponding parameters to the Analytics Service. It employs the Generative Task Handler to oversee the entire task and sends the taskId in the response.
Generative Task Handler: This functions as a controller and is part of the Analytics Service. It initially creates the taskId(a unique ID) upon receiving a request, storing this taskId and request parameters in the database. It then requests the AI service to initiate result generation. The AI service sends the parsed result to this function, which is then stored in the database corresponding to the taskId.
AI Service: This service handles result generation from the AIaaS Platform or Self-Hosted LLM. It determines which Generative Task Processor to use based on the type mentioned in the request. With the assistance of the processor function, it sends the prompt to the LLM and streams the parsed result back to the Analytics Service.
Generative Task Processors: The AI Service has different processors corresponding to each supported task. They mainly handle prompt generation from the parameters, parsing of the resultant data, and error handling.
AIaaS Platform or Self-Hosted LLM: LLM or a similar model will generate the actual result after receiving the request. These can be self-hosted or used through external providers like Azure, OpenAI, or AWS.
Database and Subscription: The back-end service opens a subscription with the help of the taskId in the Database upon receiving a request from the UI. Whenever new data is added, the Database streams it to the UI over the Subscription.
Running an Example
Let’s take the example of Article Generation from the Topic Name to get a better idea about the design.
UI will send a request with the following parameters.
// Inital Request
{
"input": {
"params": {
"articleFromTopic": {
"topicName": "Introduction to the Generative AI"
}
},
"type": "ARTICLE_FROM_TOPIC" // taskType
}
}
The request will first go to the back-end service, which will decide which service to forward the request to and redirect the input to the Analytics service.
The Generative Task Handler inside the Analytics service will act as a controller for this task. It will initially create a unique ID corresponding to the input parameters and store it in the Database along with the parameters. The Analytics service will then send this taskId to the back-end service, and the back-end service will send it to the UI as a response to the request.
// Response to the Inital Request
{
"generativeTask": {
"id": "6549ee784a0f83946f3e61c2",
"error": null,
}
}
Now, the Generative Task Handler will request the AI service to handle the result generation task with the corresponding taskId and input parameters. Based on the specified type in the input parameters, the AI service will determine which Generative Task Processor to use. In this case, it will employ the Article Processor, which will perform primarily four tasks:
Adapting the prompt according to the input parameters
Sending the request to the AIaaS Platform/Self-Hosted LLM with the help of the AI service.
Parsing the response.
Handling errors.
Here is an adapted prompt for the Article Generation Task:
SYSTEM:
Your task is to write detailed articles on the topic requested by the user. The user may provide additional clues for writing the article. The article should be written in an informative and objective tone that is accessible to a general audience. Use markdown including lists, headings, and inline styles. You may rephrase parts of user input.Use this format.
# {rephrased title}
\> {one line for subtitle; short, catchy}
{article}
## Conclusion
USER:
Write an article on the topic Introduction to the Generative AI
The AIaaS Platform will start sending the response according to the requested format in the prompt. The Article Processor will then begin parsing the response. For Article Generation, we request data in markdown format. Upon receiving each new line from the response, the processor will check for the correct markdown format and ignore it if it’s incorrect. It will then send the updated parsed result back to the Generative Task Handler inside the Analytics service.
The Generative Task Handler saves the received data in the Database.
On the UI end, once we receive the taskID, it will request to open a subscription to the back-end service. Whenever data corresponding to the taskID is updated, the updated data will be sent to the UI through the subscription.
// # Parsing process
//
// ## OpenAI Output Format ## | ## Parser Action ##
// ┌───────────────────────────────────────────────────────────────────┐
// │Sure, here... │ <- skip unknown
// │ │ <- skip empty
// │# Understanding the Node.js Event Loop │ <- add title
// │ │ <- skip empty
// │> A deep dive into Node.js' core mechanism for handling asynchronou│ <- add subtitle
// │ │ <- skip empty node
// │Node.js is a popular runtime environment that is built on top of th│ <- add node
// │ │ <- add empty node
// │## The Node.js Event Loop │ <- add node
// │ │ <- add empty node
// │At its core, the Node.js event loop is a mechanism for handling asy│ <- add node
// │ │ <- add empty node
// │```js │ <- add node, start code block
// │const fs = require('fs'); │ <- concat node
// │ │ <- concat node
// │console.log('start'); │ <- concat node
// │``` │ <- concat node, start line
// │ │ <- add empty node
// │... │
// └───────────────────────────────────────────────────────────────────┘

The state diagram of the article parser
// Parsed Result
{
"status": "completed",
"articleFromTopic": {
"title": "Understanding the Node.js Event Loop",
"subtitle": "A deep dive into Node.js' core mechanism for handling asynchronou...",
"nodes": [
{ "content": "Node.js is a popular runtime environment that is built on top of th..." },
{ "content": "" },
{ "content": "## The Node.js Event Loop" },
{ "content": "" },
{ "content": "At its core, the Node.js event loop is a mechanism for handling asy..." },
{ "content": "" },
{ "content": "```js\nconst fs = require('fs');\nconsole.log('start');\n```" },
{ "content": "" }
]
}
}
The UI will use this parsed data to display the article. Currently, we are using ProseMirror for Rich-Text Viewer and Editor on the UI.
Things to Keep in Mind:
When designing Gen-AI features, it’s essential to consider the following points based on our experience.
Showing Results Incrementally: If we take OpenAI’s GPT-3.5 as our Language Model (LLM), it takes 35 milliseconds per generated token. One hundred tokens will generate approximately 75 English words. If we aim to create a 300-word article, the LLM will take 14 seconds (300 / 75 100 35) to generate the complete result. If we display a loader for the entire duration, the waiting time will be too long for users. Therefore, it’s better to parse the result as it is being generated and display it on the UI with appropriate loaders.
Displaying Appropriate Loaders: We recommend using two different loaders on the UI. The first loader indicates the progress of the entire generative task, whether it’s completed or not. The second loader can be a typing effect or a shimmering loader to provide users with more context about what is being generated.
Error Handling: With LLMs, we have observed that they may not always adhere to the prompt instructions for the format of the resulting data. While errors are rare with popular LLMs, we need to account for this scenario. When parsing, checks should be in place to handle errors. These checks will vary depending on the scenario. For example, if you are instructing LLMs to respond in JSON format, you must validate the JSON response. If the response is corrupted, an error code should be sent, and user feedback should be provided on the UI.
Option to Give Feedback on Generated Result: Sometimes, the response may be irrelevant or inaccurate. To address such cases, a feedback mechanism can be implemented for the corresponding generated response on the UI, and user feedback can be monitored.
AIaaS Platform Agnostic Design: Design and code your system in a way that doesn’t depend on a specific AIaaS platform or LLM. Different platforms are continually improving and offering more cost-effective solutions, so you should leverage the competition.
Token Limits and Errors: If you are using AIaaS platforms, you have to consider the number of tokens (which can be imagined as the number of words) you are using, as you will be charged based on that. You can’t include unnecessary words in the context of your prompt, as they will be appended to every request, and you will be charged for those words in every request. In such scenarios, Prompt Engineering will come in handy. You also have to consider token-exceeded errors in your Generative Task Processors.
Parsing Output: Although it is possible to get structured data from LLM, parsing partial JSON for streaming may introduce complexities. In many cases, the output might be more predictable when presented in natural language, while also allowing incremental parsing as the content is being generated. When using English tokens as delimiters for parsing, it’s important to anticipate scenarios where users may request translations or input their queries in languages other than English. Delimiters based on English tokens may not align with the linguistic structure of other languages, potentially leading to parsing inaccuracies.
References
Response Times: https://www.taivo.ai/__gpt-3-5-and-gpt-4-response-times/
Token Size: https://help.openai.com/en/articles/4936856-what-are-tokens-and-how-to-count-them